-- LiXizhi - 2008-06-13
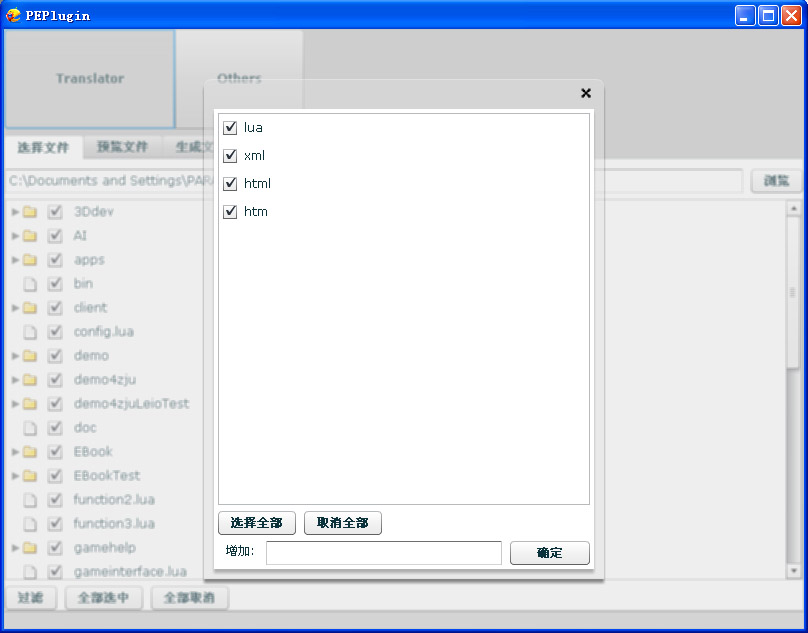
 这里你还可以选择要选中的文件类型。
这里你还可以选择要选中的文件类型。
 二:预览文件
缩略列表:只显示选中的文件和文件夹。
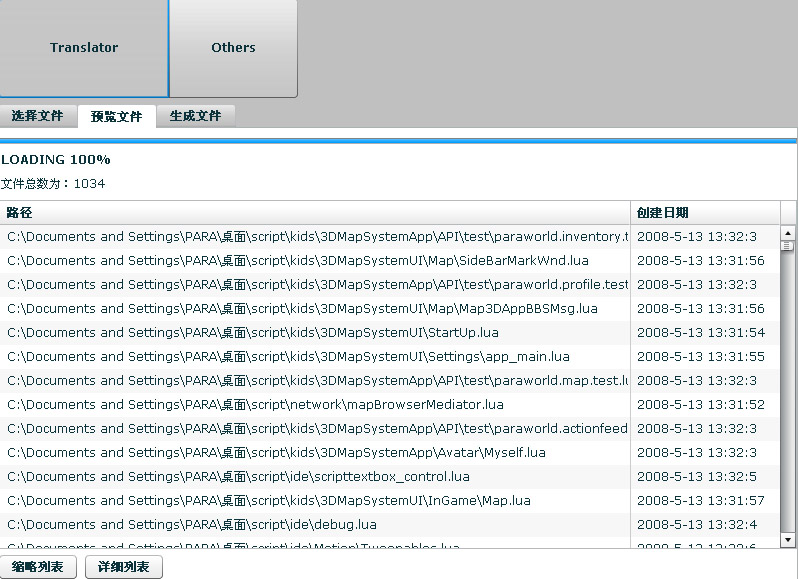
二:预览文件
缩略列表:只显示选中的文件和文件夹。
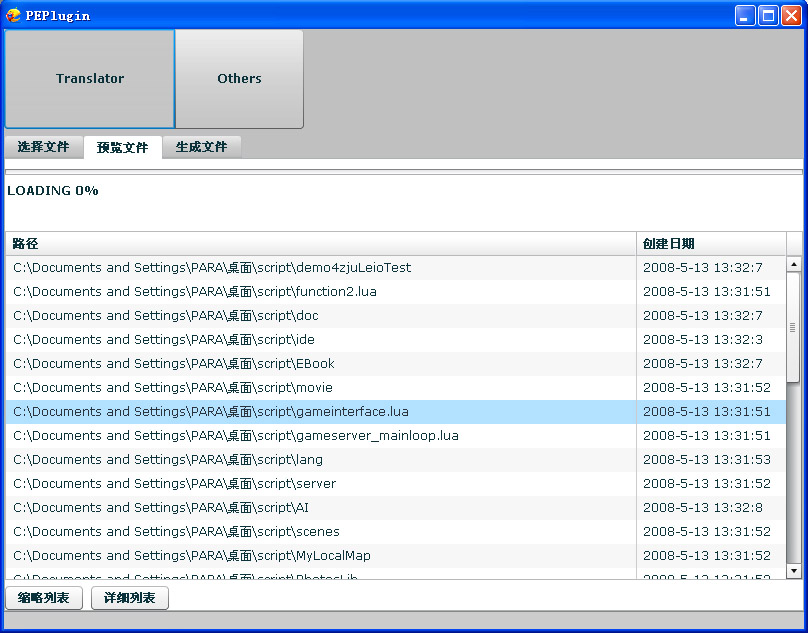 详细列表:显示所有文件的全路径。
详细列表:显示所有文件的全路径。
 三:生成文件
三:生成文件 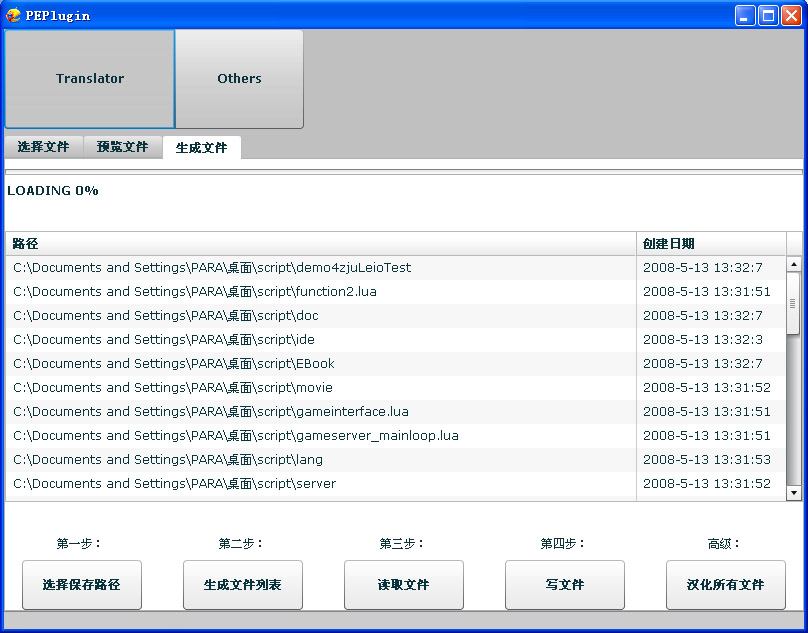 主要实现原理:
一:查找NPL文件
主要实现原理:
一:查找NPL文件
Translators
Translators是一个为NPL和MCML文件专门设计的查找中文字符的工具。 支持文件类型: 使用指南 一:选择文件 选择一个文件,查找的结果将会存在这里。
这里你还可以选择要选中的文件类型。
二:预览文件
缩略列表:只显示选中的文件和文件夹。
详细列表:显示所有文件的全路径。
三:生成文件 - 选择保存路径(选择一个文件,查找的结果将会存在这里)
- 生成文件列表(把选中的文件全部转换成详细路径。)
- 读取文件(查找每一个文件里面的中文字符,这可能需要一些时间。)
- 写文件(把查找的结果存储到"第一步"选择的位置。)
- 汉化所有文件(汉化所有包含中文字符的文件,并把这些文件保存到"第一步"的"Translation"目录下面。)
主要实现原理:
一:查找NPL文件 - 读取一个NPL文件以后,去掉所有的注释,返回txt。
- 删除txt中所有匹配string.format() 的字符串,并把包含中文字符串 的string.format() 记录下来。
- 删除txt中所有匹配[ [ ... ] ]的字符串,并把包含中文字符串 的[ [...] ]记录下来。
- 以英文的双引号 (")为分隔符,分离剩余的字符串,找出每个包含中文字符的字符串,并把它记录下来。
- 修饰MCML文件为标准的XML文件格式,( 1.1:去掉 < DOCTYPE.*?\ > ) (1.2: 删除所有< %...% >,并把包含中文字符串的记录下来)(1.3:加上命名空间< temp xmlns:pe='http://www.pala5.com/pe-mcml' / >)
-
构造XML,遍历所有XML的节点和属性,找出所有包含中文字符的字符串,如果是< script >节点,把它看做NPL文件进行解析。


| I | Attachment | History | Action | Size |
Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
2.jpg | r2 r1 | manage | 85.1 K | 2008-06-13 - 09:30 | UnknownUser | |
| |
1.jpg | r2 r1 | manage | 95.8 K | 2008-06-13 - 09:29 | UnknownUser | |
| |
5.jpg | r2 r1 | manage | 148.1 K | 2008-06-13 - 09:30 | UnknownUser | |
| |
3.jpg | r2 r1 | manage | 161.5 K | 2008-06-13 - 09:30 | UnknownUser | |
| |
4.jpg | r2 r1 | manage | 201.1 K | 2008-06-13 - 09:30 | UnknownUser |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This topic: Main > NPLDocsVersion1 > NplLocalization
Topic revision: r3 - 2008-06-16 - LeioZhang
Ideas, requests, problems regarding TWiki? Send feedback